Context
When I first moved to Brooklyn, NY to work for Teachers Pay Teachers I was on the hunt for new and interesting destinations to explore. I also knew TpT used ReactJS and began getting the itch to bootstrap my skills with a side project.
At around the same time my buddy Alek moved to Queens and was finishing up a developer bootcamp.
Given Alek and I both consider breweries our favorite type of establishment, we set a date to go explore some nearby. We hopped online and started looking for a visually pleasing map that showcased breweries similar to this map of VT. To our surprise, we couldn’t find something that was both as complete and as simple as the VT map!
Inspiration struck! We set out to build Brewery Life to not only satisfy our inner explorers but also to build something using React together!
Brewery Life
We wanted to give people an unbiased, holistic view of each venue. We figured if we could aggregate information from various sources where people were already leaving reviews, we could hit the ground running with content. So, we aggregated the following information:
- Location - Google
- Images - Google
- Reviews - Google, Yelp, Foursquare, Untappd
- Hours / Phone - Google
- Beers - Untappd
- Social - Untappd
Technology
We hit the ground running thanks to create-react-app. After gluing together some open source components that allowed us to display a map with some markers on it, we wanted to show our friends!
I had heard a lot about serverless architectures on software engineering daily and wanted to internalize the concepts. I had plenty of experience with AWS and figured this could be an opportunity to run a site without any infrastructure maintenance burden. I realized we could leverage Travis CI to both test and build Brewery Life on every merge to master. We could then automate storing the built files in AWS S3 fronted by Cloudfront as our content delivery network.
We also reached out to Travis CI about their beta CRON job functionality and they graciously opted us in. Our build and deploy job runs once a day to ensure our images, reviews and beers are up to date.
Architecture
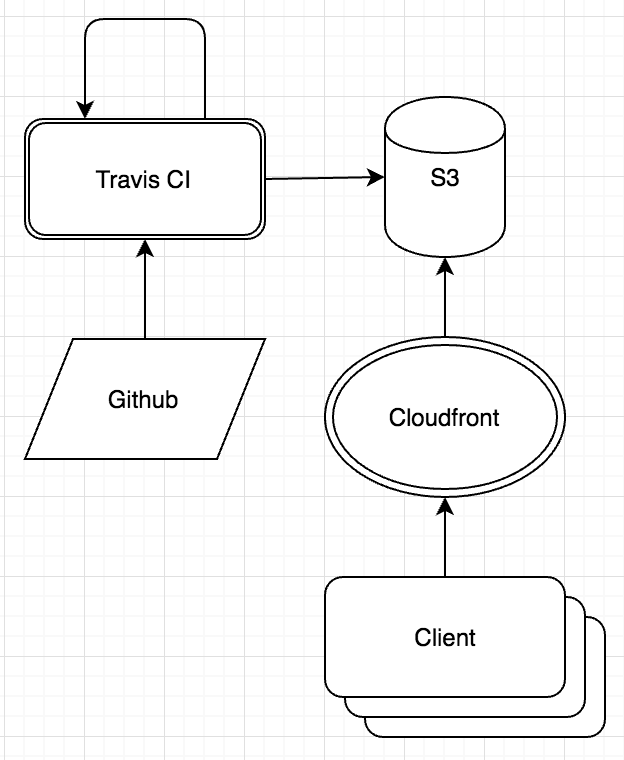
We don’t maintain any of it!!
Build
Minimum Viable Product
Our entire application is driven by a singular breweries.json configuration file that is bundled into our payload via webpack via an import in our top level component.
We wrote a small NodeJS script called update-breweries.js that generates breweries.json based on a config.json that contains a curated list of breweries. For our first cut, we checked both files in to master and simply had Travis CI run yarn build and aws s3 sync.
Sitemap.xml
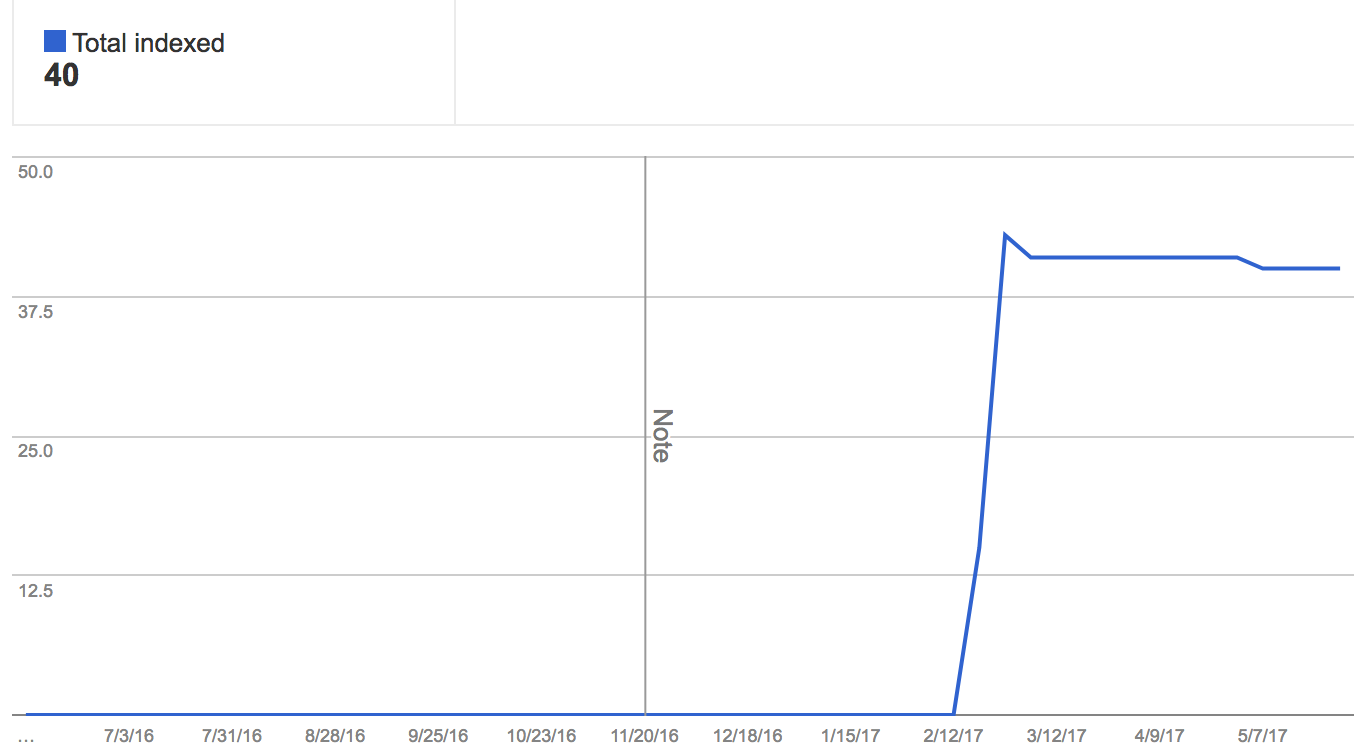
We wanted to see if we could get some organic traffic to our site, so started toying around with SEO. Step one was to generate a sitemap.xml.
sitemap.xml was dynamically generated based on the same root config.json file via a react-router path convention we determined (/city/BreweryName/). Almost immediately upon including the sitemap.xml and updating Google’s Search Console, we saw a big spike in indexed pages!
SEO
Our next step was to include some schema.org metadata in our markup. We were able to include lots of entities throughout our site, including the somewhat obscure Brewery!
Unfortunately, once we did this, we weren’t seeing the Search Console recognize our metadata. What was going on?
We decided to use the Fetch as Google tool to see what Google was seeing. This was the result:

Even though Google was indexing all of our pages, it wasn’t actually seing any information on them!
It seemed like the Googlebot wasn’t downloading and executing our Javascript bundle in the same way the browser would.
Normally, this type of problem could be solved by server side rendering - but we were dedicated to serverless!
Server side rendering?
Is there any way we could return HTML to Googlebot that would allow it to understand what our pages were all about? What if we pre-generated all of our HTML pages and stored them in S3 such that any one of them would be a viable entry point into the application?
Enter selenium and chromedriver! By simply hosting a server as part of the build phase, visiting every page and saving the resultant HTML to disk, we were able to replicate server side rendering.
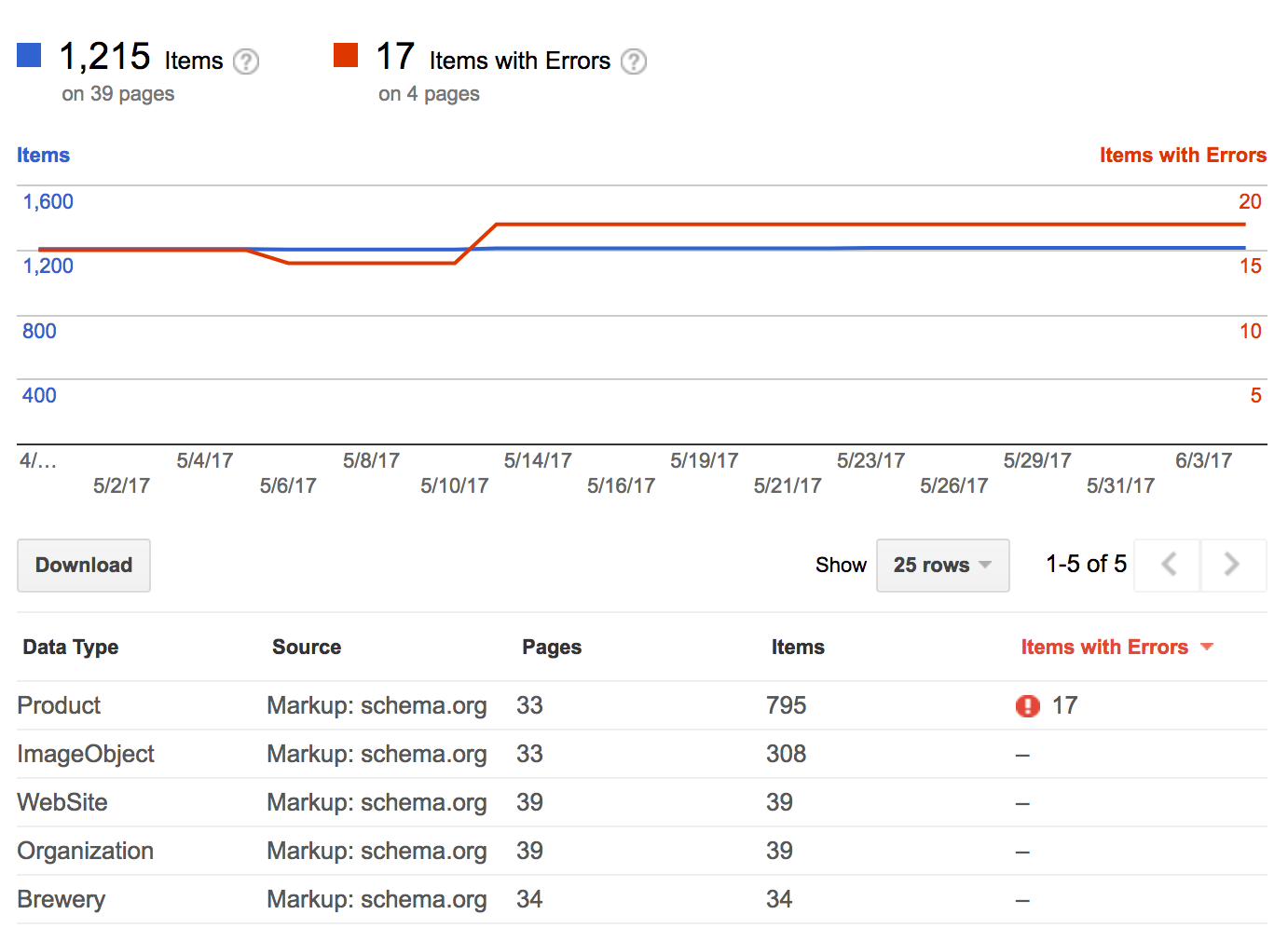
Once we implemented this, the Fetch as Google tool was able to see our content:

We also saw the search console pick up all of the objects we declared in our markup:
Stale content
Now that we had a relatively robust build process that was able to aggregate data from various sources, optimize the site for SEO and update the infrastructure - we had to ensure the content didn’t get stale! Enter Travis CI CRON jobs. We configured the job to run our deploy script once daily.
Speed
There were two primary avenues we explored for speed:
gzip
We were able to use the gzip command line utility with the -9 flag to ensure all of our content was compressed to the maximum setting gzip offers. We then uploaded files to s3 using the Content-Encoding: gzip headers and Cloudfront took care of the rest!
Service Workers
Service workers are able to locally cache dynamic assets in the browser based on a simple configuration. We were able to configure our service worker to not only cache our Javascript, but also some of the libraries we depend on for a [Progressive Web Application]() experience. Check out our [sw-precache-config.js]() file for details.
What’s next?
We are thinking about adding a can trading network to the site. This would likely mean we need to introduce the concept of a user. In order to keep with our serverless constraint, we’d likely use API Gateway, Lambda and DynamoDB to store and retrieve that information.
Conclusion
Building a non trivial serverless website definitely comes with it’s own unique set of challenges. However, given that there’s zero maintenance overhead, I’d absolutely make the same decisions in hindsight!