Originally posted here. Referenced by Kaltura here.
We’re always working to build new products and features that will help our Teacher-Author community empower educators to teach at their best. This past year, some of our team was working on core infrastructure which blocked many potential changes to our existing products. Adding to our core product was available to us so we embarked on an extensive analysis via user testing to determine where to focus our energy. We determined that streaming video was an excellent medium that our Teacher-Authors could use to convey complex information so we introduced it on Teachers Pay Teachers. Here’s an example video.
As always, we wanted to ensure that any work we did focused on educators. This meant it didn’t make sense for us to learn how to build video storage, transcoding, or streaming functionality. Naturally, we sought out a third party provider to help us out. We looked for a partner that offered us all of the following at a reasonable cost:
- Uploading / Hosting
- Transcoding
- Multi-platform playback
- Well documented, feature rich API
- Scalability
- Authentication (or the ability to hide video behind a paywall)
We were able to quickly narrow the field to three potential candidates: Brightcove, Ooyala, and Kaltura. We chose Kaltura based on their competitive price point, developer friendliness and product roadmap alignment with the education technology landscape (e.g. interactive quizzes).
The goal of this post is to outline our video processing infrastructure and dive deeply into some of the technical issues we faced while releasing our minimal viable streaming video product.
Here’s our high level systems architecture that outlines the flow of bytes from an educator’s machine into our systems:
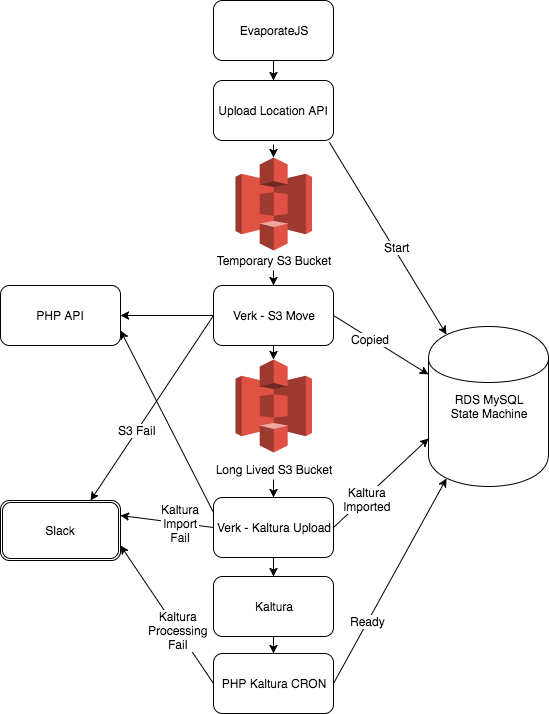
Definitions of the systems pictured in the architecture diagram:
- Kaltura - video hosting provider
- RDS MySQL - state machine storage
- Verk - queue processing system
- AWS S3 - Amazon Simple Storage Service for video file storage
- EvaporateJS - JS library to upload files directly from the browser to AWS S3.
- Slack - chat room with channels dedicated to alerting us about processing failures
TpT PHP- custom PHP written by us that contains business logic
We leverage S3 quite heavily for other uploads so made the practical decision to utilize the same modules for video uploads. Having copies of the data originally uploaded in S3 gives us additional reliability in case something were to go awry.
After building and releasing this infrastructure to a small group of beta testers, we saw a small number of issues with the upload flow: approximately 5% of uploads resulted in a failure. These failures manifested in the following ways:
Status: Uploading (forever!)
Our initial implementation downloaded files onto our servers and then uploaded them to Kaltura via their PHP SDK upload API. This API required sending the file in chunks. Unfortunately, we were never able to get Kaltura to recognize that our chunked files were finished uploading, resulting in the files in question remaining permanently in Kaltura’s Uploading status. After searching for alternatives, we discovered their upload from URL API and realized we could generate temporarily authorized URLs from S3 that would allow Kaltura to directly consume videos from AWS S3 without giving them permenant access. This change cleaned up approximately 90 lines of code, reduced costs by limiting our S3 download bandwidth and simplified our interaction with Kaltura!
S3 Exception - File Not Found
Our PHP API - S3 Move job copies files from a temporary, public s3 bucket to a more restricted permanent home and then deletes the original file. We were seeing failures at this step claiming the file we were attempting to move did not exist! After a ton of digging, we discovered that files were making it from the browser to S3 but had a different name than what we were expecting.
Before beginning each upload, we randomly generate a file name in the Upload Location API. This filename is then passed along to the PHP API - S3 Move job. EvaporateJS utilizes localStorage to allow resuming of uploads in the case of intermittent failures. What we stumbled upon was Evaporate’s add function’s complete callback signature:
function(xhr, awsObjectKey, stats) { }
a function that will be called when the file upload is complete. Version 1.0.0 introduced the awsObjectKey parameter to notify the client of the S3 object key that was used if the object already exists on S3.
We had incorrectly assumed that Evaporate would always use the path we gave it when beginning an upload - an assumption that proved false when an upload was resumed! We added this small conditional and saw approximately 80% of our FileNotFound exceptions disappear:
function (xhr, awsObjectKey, stats) {
if (awsObjectKey !== originalPath) {
// handle case where we resumed
} else {
// handle the happy path
}
}
S3 Exception - File Not Found… again?!
Unfortunately, the proper usage of Evaporate’s complete' callback did not completely resolve the FileNotFound problem. We began theorizing that a large file size was correlated with an increased rate of error. I began asking myself, “what are we doing differently between small and large files?” and remembered the following code snippet inside of thePHP API - S3 Move` job:
<?php
// this was always set to true for video files
if ($useMultipart) {
(new \Aws\S3\ObjectCopier($this->_client, $options))->copy();
} else {
$this->_client->copyObject($options);
}
?>
We originally wrote this due to Amazon’s requirement to use multipart operations for objects larger than 5GB. Given video files can easily exceed 5GB, we opted-in to multipart operations by default. Rather than make this decision ourselves, we transitioned to Amazon’s higher level copy API which internally handles toggling between direct and multipart operations based on object size. The above conditional was replaced by:
<?php
$this->_client->copy($source->s3Bucket,
$source->path,
$target->s3Bucket,
$target->path,
'bucket-owner-full-control',
$options);
?>
This further reduced the number of errors by limiting multipart operations to situations where they were strictly necessary. Unfortunately, this change began surfacing a new error in our logs.
MultipartUploadException
A ha! Previously, we were swallowing AWS SDK exceptions and disguising them with a more generic exception. MultipartUploadExceptions were easy to gracefully handle by retrying just the parts that had failed. Here’s a small snippet that demonstrates our current usage of the copy interface.
<?php
while($result===null && $retries < 10) {
try {
$result = $this->_client->copy($params);
} catch(\Aws\S3\Exception\S3Exception $e) {
throw $e;
} catch(\Aws\Exception\MultipartUploadException $e) {
$options['state'] = $e->getState();
$retries++;
$retry_sleep = pow($retries, 2);
sleep($retry_sleep);
}
}
?>
S3 Exception - File Still Not Found :(
At this point, we had reduced the reported error rate from 5% to under 1%. Strangely enough, many of the videos that our logs reported errors for were, in fact, ready for viewing. After scouring through Verk’s documentation this line caught our eye:
The jobs that will run on top of Verk should be idempotent as they may run more than once.
Our PHP API - S3 Move endpoint was not idempotent as it deleted the original file after copying it. At this point, there were two possibilities:
- Verk was running the same job multiple times
- Something went wrong during the processing pipeline and caused Verk to retry a failed job with exponential backoff
It turns out both of these things were happening!
We stopped relying on our PHP API - S3 Move endpoint to clean up after itself and transitioned to AWS S3 Object Lifecycles to automatically clean up uploaded files after a certain period of time. This means our job is now idempotent and can be retried ad infinitum until our Lifecycle policy kicks in.
But why were retrying at all?
As a reminder, these Verk jobs are simple wrappers around our PHP API. The endpoints in question are responsible for manipulating video files which are often quite large. We figured it might be possible that calls to our API were exceeding our configured 10 minute timeout. Turns out, we hadn’t read the docs correctly and configured HTTPoison using seconds instead of milliseconds! Doh! This was causing many of our PHP API calls to time out which triggered one of Verk’s core features: Retry mechanism with exponential backoff! We simply updated the timeout configuration as follows:
def call_php_api(name, args) do
body =
%{"name" => name, "args" => args}
|> Poison.encode
|> elem(1)
HTTPoison.post!(url, body, headers, hackney: [{:timeout, 1002*1000}, {:recv_timeout, 1002*1000}])
|> handle_response!(name)
end
Wrapping Up
Due to these improvements in our infrastructure we’ve been able to successfully release video to our community! As of now, we have an ever growing library of approximately 3000 videos that help communicate concepts across an enormous breadth of topics. This foundation has paved the way for us to accelerate growth in our streaming video product and created new opportunities for our community!